from numpy import nan as NAimport pandas as pddata = pd.DataFrame([[1., 6.5, 3.], [1., NA, NA], [NA, NA, NA], [NA, 6.5, 3.]])cleaned = data.dropna()print(cleaned)print(data.dropna(how='all'))data[4] = NAprint(data.dropna(how='all', axis=1))print(data)print(data.fillna(0))print(data.fillna({1: 0.5, 2: 0}))
0 1 2
0 1.0 6.5 3.0
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
3 NaN 6.5 3.0
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
0 1 2 4
0 1.0 6.5 3.0 NaN
1 1.0 NaN NaN NaN
2 NaN NaN NaN NaN
3 NaN 6.5 3.0 NaN
0 1 2 4
0 1.0 6.5 3.0 0.0
1 1.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 0.0 6.5 3.0 0.0
0 1 2 4
0 1.0 6.5 3.0 NaN
1 1.0 0.5 0.0 NaN
2 NaN 0.5 0.0 NaN
3 NaN 6.5 3.0 NaN
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
6 two 4
0 False
1 False
2 False
3 False
4 False
5 False
6 True
dtype: bool
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
import pandas as pddata = {'A': ['1', '2', '3', '4', '5', '6'],'B': ['7.5', '8.5', '9.5', '10.5', '11.5', '12.5'],'C': ['x', 'y', 'z', 'x', 'y', 'z']}data2 = pd.DataFrame(data)# Wyświetlenie oryginalnej ramki danychprint("Oryginalna ramka danych:")print(data2)# Zmiana typu danych kolumny 'A' na intdata2['A'] = pd.Series(data2['A'], dtype=int)# Zmiana typu danych kolumny 'B' na floatdata2['B'] = pd.Series(data2['A'], dtype=float)# Wyświetlenie ramki danych po zmianie typówprint("\nRamka danych po zmianie typów:")print(data2)
Oryginalna ramka danych:
A B C
0 1 7.5 x
1 2 8.5 y
2 3 9.5 z
3 4 10.5 x
4 5 11.5 y
5 6 12.5 z
Ramka danych po zmianie typów:
A B C
0 1 1.0 x
1 2 2.0 y
2 3 3.0 z
3 4 4.0 x
4 5 5.0 y
5 6 6.0 z
import pandas as pddata = {'A': ['1', '2', '3', '4', '5', '6'],'B': ['7.5', '8.5', '9.5', '10.5', '11.5', '12.5'],'C': ['x', 'y', 'z', 'x', 'y', 'z']}data2 = pd.DataFrame(data)# Wyświetlenie oryginalnej ramki danychprint("Oryginalna ramka danych:")print(data2)# Zmiana typu danych kolumny 'A' na intdata2['A'] = data2['A'].astype(int)# Zmiana typu danych kolumny 'B' na floatdata2['B'] = data2['B'].astype(float)# Wyświetlenie ramki danych po zmianie typówprint("\nRamka danych po zmianie typów:")print(data2)
Oryginalna ramka danych:
A B C
0 1 7.5 x
1 2 8.5 y
2 3 9.5 z
3 4 10.5 x
4 5 11.5 y
5 6 12.5 z
Ramka danych po zmianie typów:
A B C
0 1 7.5 x
1 2 8.5 y
2 3 9.5 z
3 4 10.5 x
4 5 11.5 y
5 6 12.5 z
25.8 Zmiana znaku kategoriach
import pandas as pd# Tworzenie ramki danychdata = {'A': ['abc', 'def', 'ghi', 'jkl', 'mno', 'pqr'],'B': ['1.23', '4.56', '7.89', '0.12', '3.45', '6.78'],'C': ['xyz', 'uvw', 'rst', 'opq', 'lmn', 'ijk']}data2 = pd.DataFrame(data)# Wyświetlenie oryginalnej ramki danychprint("Oryginalna ramka danych:")print(data2)# Zmiana małych liter na duże w kolumnie 'A'data2['A'] = data2['A'].str.upper()# Zastąpienie kropki przecinkiem w kolumnie 'B'data2['B'] = data2['B'].str.replace('.', ',')# Wyświetlenie ramki danych po modyfikacjiprint("\nRamka danych po modyfikacji:")print(data2)
Oryginalna ramka danych:
A B C
0 abc 1.23 xyz
1 def 4.56 uvw
2 ghi 7.89 rst
3 jkl 0.12 opq
4 mno 3.45 lmn
5 pqr 6.78 ijk
Ramka danych po modyfikacji:
A B C
0 ABC 1,23 xyz
1 DEF 4,56 uvw
2 GHI 7,89 rst
3 JKL 0,12 opq
4 MNO 3,45 lmn
5 PQR 6,78 ijk
right: ramka danych, którą chcesz dołączyć do oryginalnej ramki danych.
how: określa typ łączenia. Dostępne są cztery typy: ‘inner’, ‘outer’, ‘left’ i ‘right’. ‘inner’ to domyślna wartość, która zwraca tylko te wiersze, które mają pasujące klucze w obu ramkach danych.
on: nazwa lub lista nazw, które mają być używane do łączenia. Musi to być nazwa występująca zarówno w oryginalnej, jak i prawej ramce danych.
left_on i right_on: nazwy kolumn w lewej i prawej ramce danych, które mają być używane do łączenia. Można to użyć, jeśli nazwy kolumn nie są takie same.
left_index i right_index: czy indeksy z lewej i prawej ramki danych mają być używane do łączenia.
sort: czy wynikowa ramka danych ma być posortowany według łączonych kluczy.
suffixes: sufiksy, które mają być dodane do nazw kolumn, które nachodzą na siebie. Domyślnie to (’_x’, ’_y’).
copy: czy zawsze kopiować dane, nawet jeśli nie są potrzebne.
indicator: dodaj kolumnę do wynikowej ramki danych, która pokazuje źródło każdego wiersza.
validate: sprawdź, czy określone zasady łączenia są spełnione.
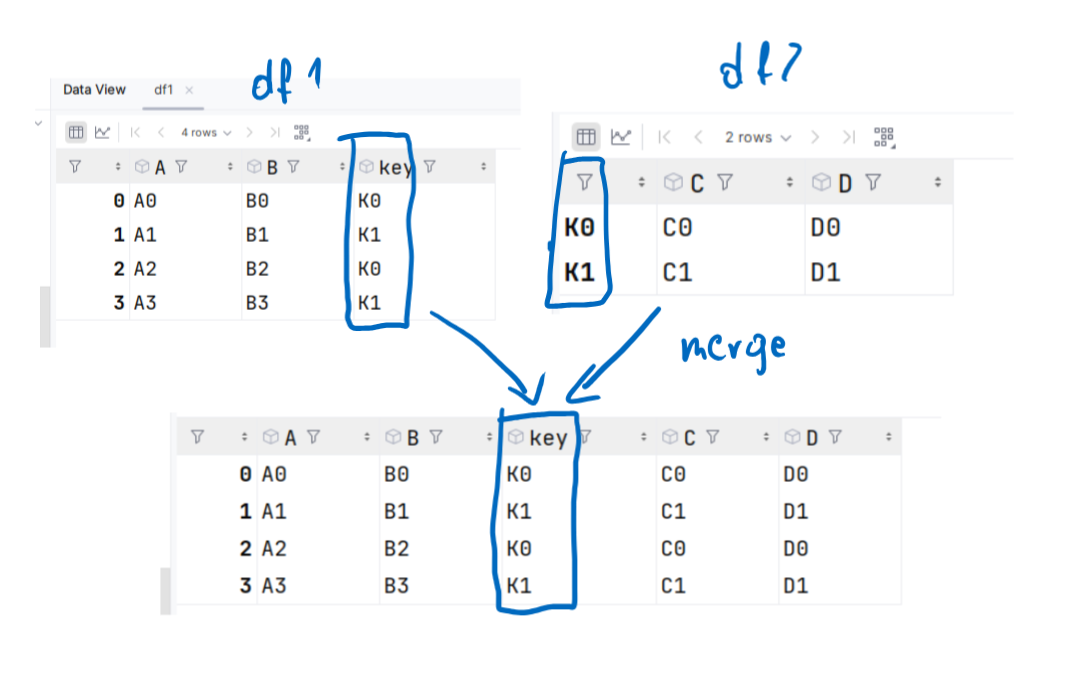
key A B
0 K0 A0 B0
1 K1 A1 B1
2 K2 A2 B2
3 K3 A3 B3
key C D
0 K0 C0 D0
1 K1 C1 D1
2 K4 C2 D2
3 K5 C3 D3
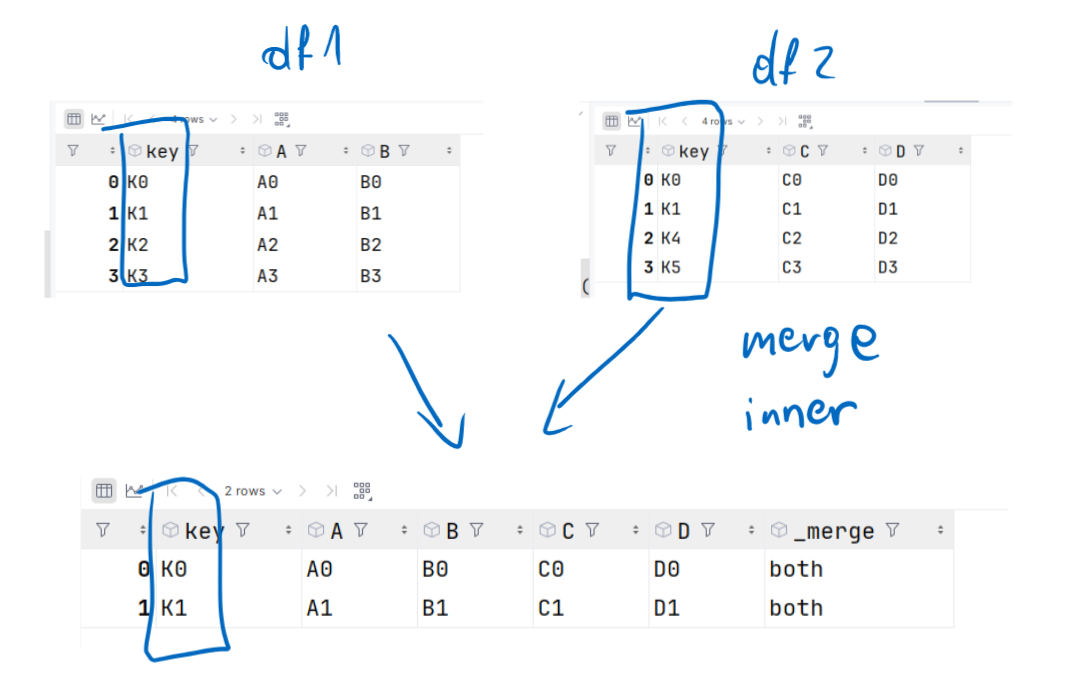
Inner join
key A B C D _merge
0 K0 A0 B0 C0 D0 both
1 K1 A1 B1 C1 D1 both
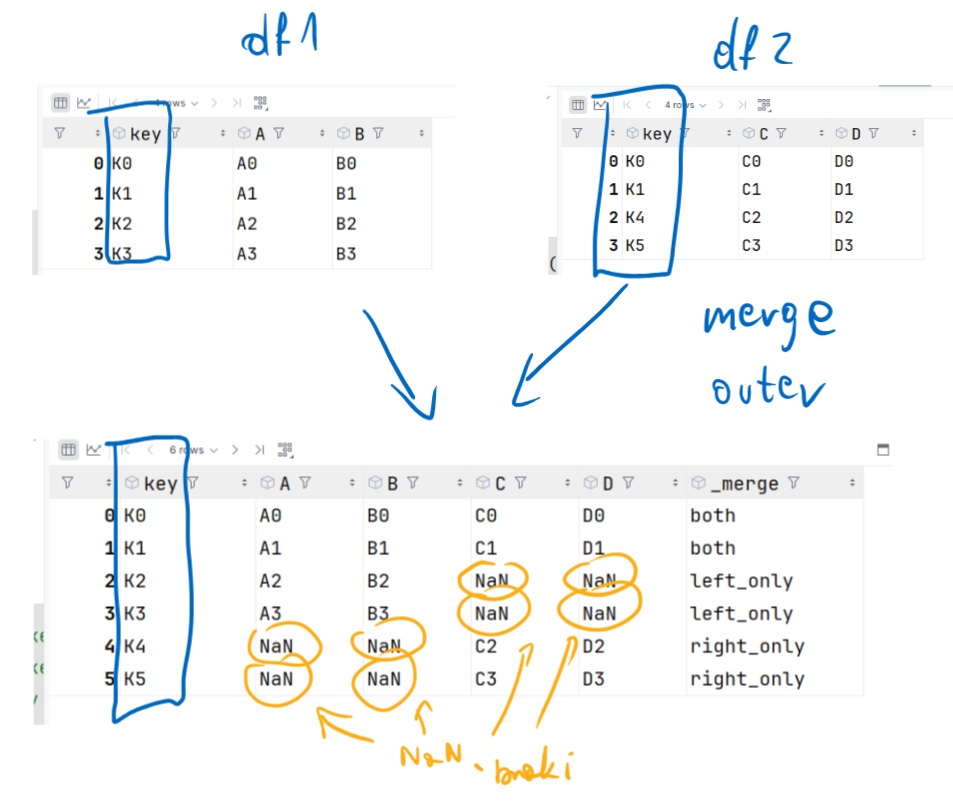
Outer join
key A B C D _merge
0 K0 A0 B0 C0 D0 both
1 K1 A1 B1 C1 D1 both
2 K2 A2 B2 NaN NaN left_only
3 K3 A3 B3 NaN NaN left_only
4 K4 NaN NaN C2 D2 right_only
5 K5 NaN NaN C3 D3 right_only
Left join
key A B C D _merge
0 K0 A0 B0 C0 D0 both
1 K1 A1 B1 C1 D1 both
2 K2 A2 B2 NaN NaN left_only
3 K3 A3 B3 NaN NaN left_only
Right join
key A B C D _merge
0 K0 A0 B0 C0 D0 both
1 K1 A1 B1 C1 D1 both
2 K4 NaN NaN C2 D2 right_only
3 K5 NaN NaN C3 D3 right_only
other: ramka danych, którą chcesz dołączyć do oryginalnej ramki danych.
on: nazwa lub lista nazw kolumn w oryginalnej ramxce danych, do których chcesz dołączyć.
how: określa typ łączenia. Dostępne są cztery typy: ‘inner’, ‘outer’, ‘left’ i ‘right’. ‘left’ to domyślna wartość, która zwraca wszystkie wiersze z oryginalnej ramki danych i pasujące wiersze z drugiej ramki danych. Wartości są uzupełniane wartością NaN, jeśli nie ma dopasowania.
lsuffix i rsuffix: sufiksy do dodania do kolumn, które się powtarzają. Domyślnie jest to puste.
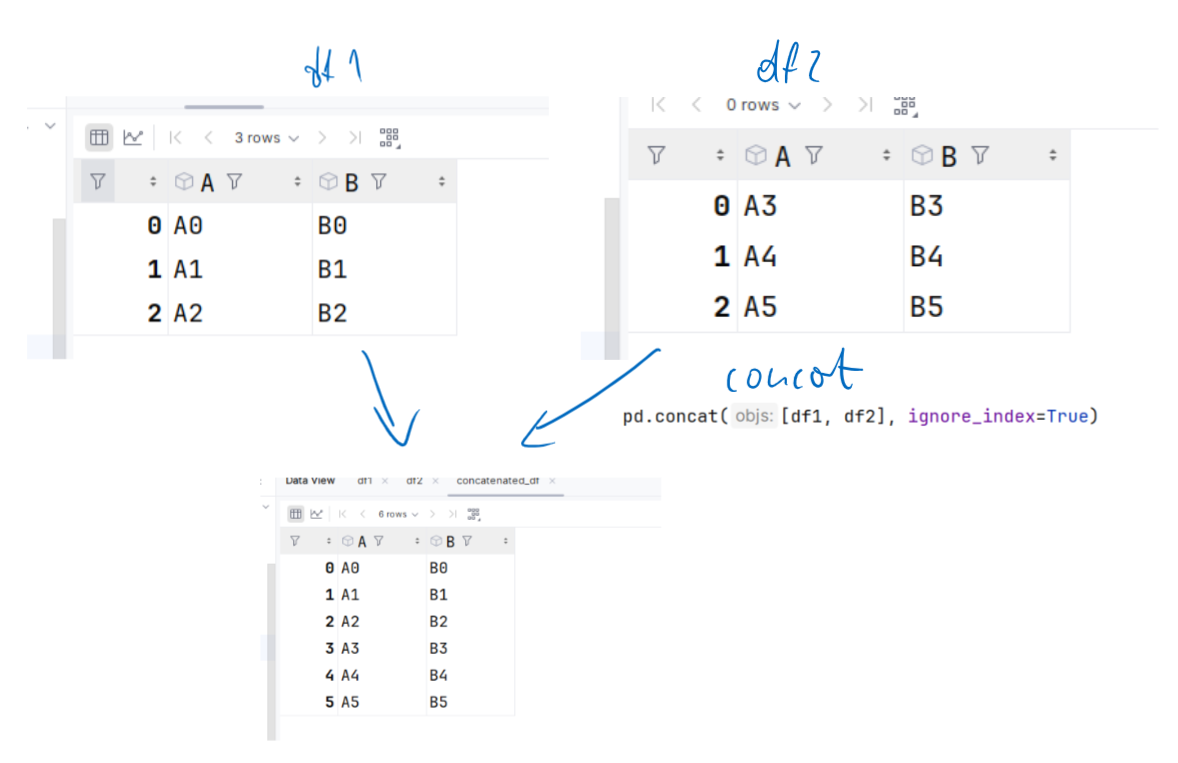
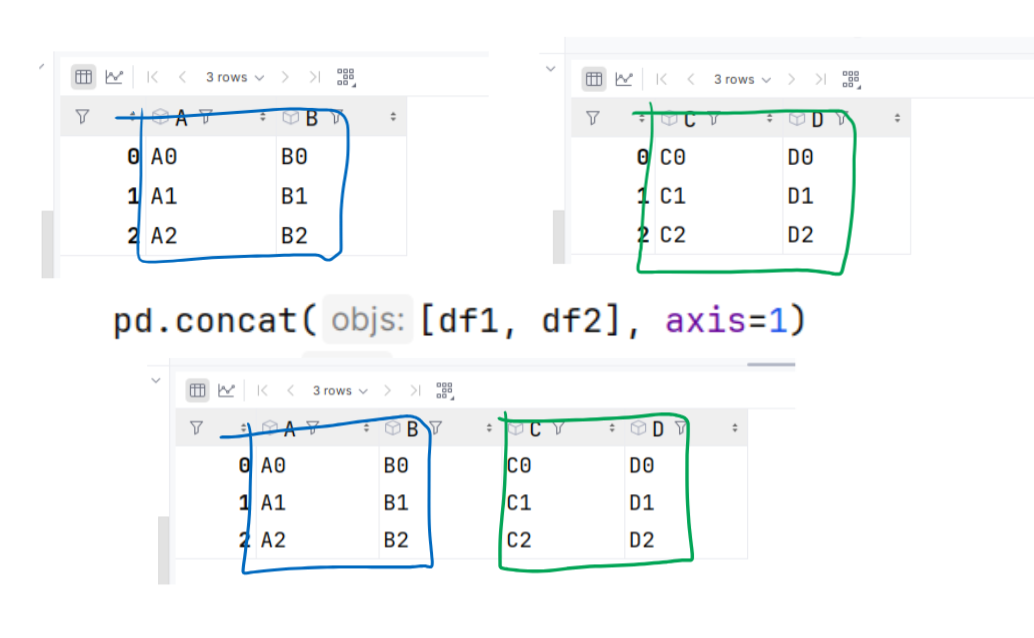
objs: sekwencja ramek danych, które chcesz połączyć.
axis: oś, wzdłuż której chcesz łączyć ramki danych. Domyślnie to 0 (łączenie wierszy, pionowo), ale można także ustawić na 1 (łączenie kolumn, poziomo).
join: określa typ łączenia. Dostępne są dwa typy: ‘outer’ i ‘inner’. ‘outer’ to domyślna wartość, która zwraca wszystkie kolumny z każdej ramki danych. ‘inner’ zwraca tylko te kolumny, które są wspólne dla wszystkich ramek danych.
ignore_index: jeśli ustawione na True, nie używa indeksów z ramek danych do tworzenia indeksu w wynikowej ramce danych. Zamiast tego tworzy nowy indeks od 0 do n-1.
keys: wartości do skojarzenia z obiektami.
levels: określone indeksy dla nowej ramki danych.
names: nazwy dla poziomów indeksów (jeśli są wielopoziomowe).
verify_integrity: sprawdza, czy nowy, skonkatenowana ramka danych nie ma powtarzających się indeksów.
sort: czy sortować niekonkatenacyjną oś (np. indeksy, jeśli axis=0), niezależnie od danych.
copy: czy zawsze kopiować dane, nawet jeśli nie są potrzebne.
A B
0 A0 B0
1 A1 B1
2 A2 B2
C D
0 C0 D0
1 C1 D1
2 C2 D2
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
A B C D
df1 0 A0 B0 NaN NaN
1 A1 B1 NaN NaN
2 A2 B2 NaN NaN
df2 0 NaN NaN C0 D0
1 NaN NaN C1 D1
2 NaN NaN C2 D2
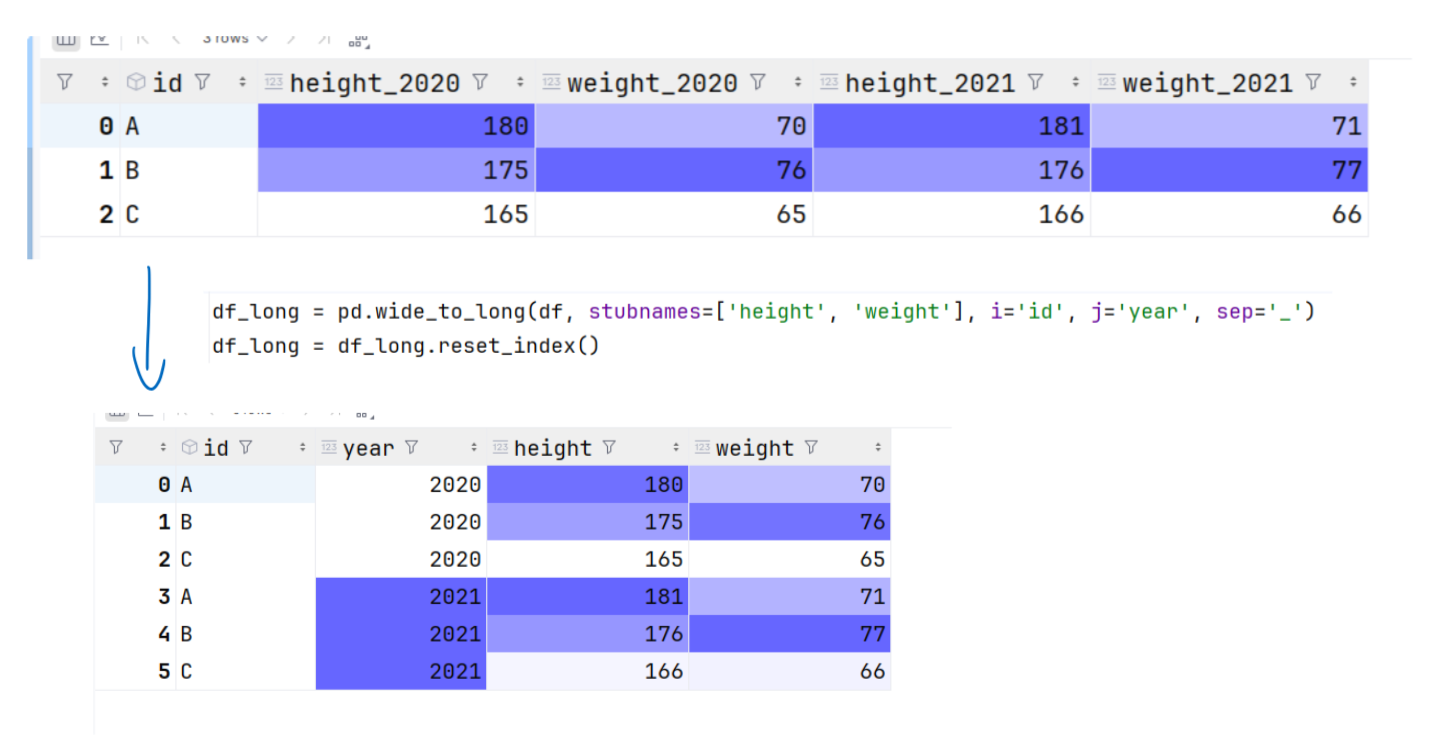
Metoda wide_to_long jest używana do przekształcenia danych z szerokiego formatu (gdzie każda kolumna zawiera wiele zmiennych) do długiego formatu (gdzie każda kolumna zawiera jedną zmienną z wieloma pomiarami). Jest to przydatne, gdy mamy dane, które są rozłożone w wielu kolumnach z powtarzającymi się lub sekwencyjnymi nazwami, i chcemy przekształcić te dane w sposób, który ułatwia analizę i wizualizację.
Wyjaśnienie parametrów wide_to_long
stubnames: Lista początkowych części nazw kolumn, które mają zostać przekształcone.
i: Nazwa kolumny lub lista kolumn, które identyfikują poszczególne wiersze. W naszym przykładzie jest to id, które unikalnie identyfikuje osobę.
j: Nazwa nowej kolumny, w której będą przechowywane różne poziomy zmiennych (w naszym przypadku rok).
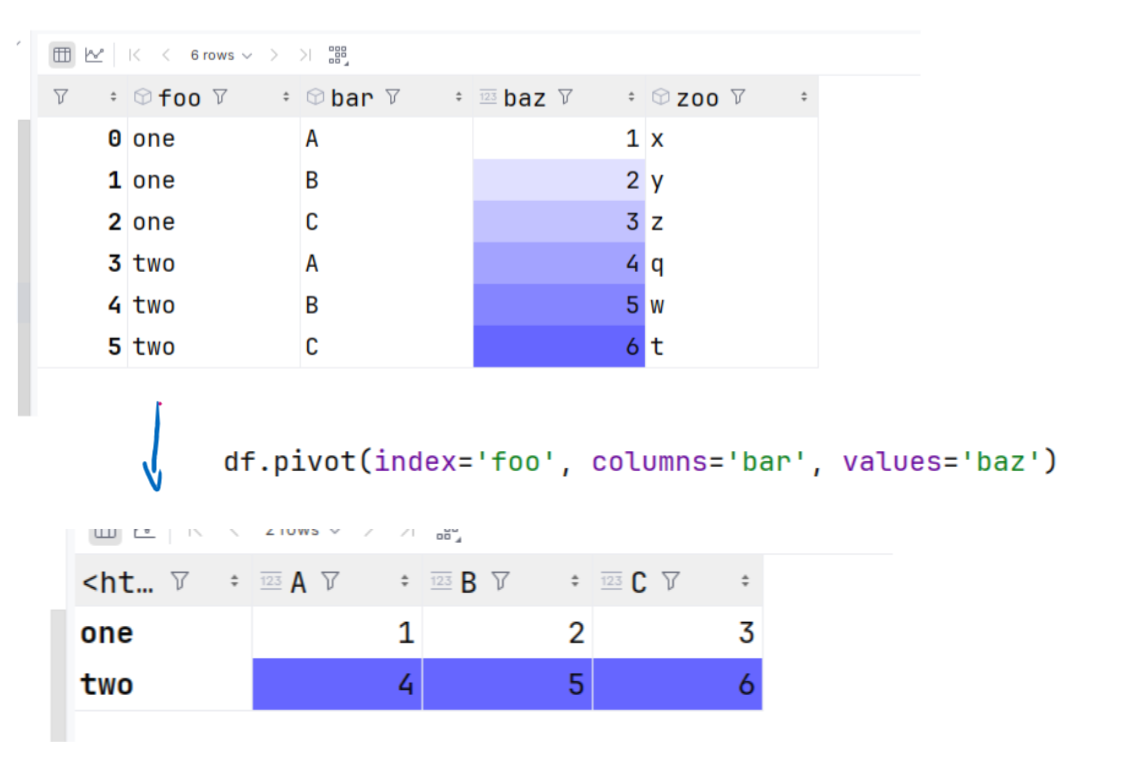
A B C D
0 foo one 2.0 3.0
1 bar one 1.0 2.0
2 baz two 3.0 1.0
A B My_Var My_Val
0 foo one C 2.0
1 bar one C 1.0
2 baz two C 3.0
3 foo one D 3.0
4 bar one D 2.0
5 baz two D 1.0