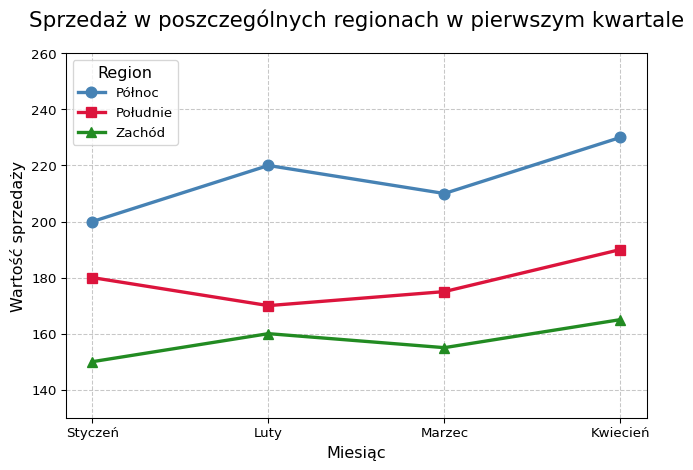
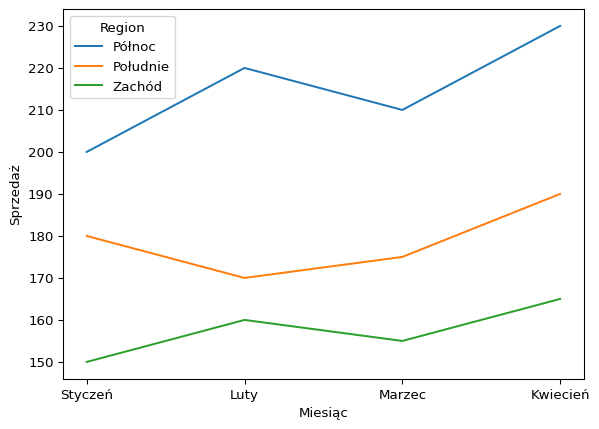
Cel dodatkowy: różnice miedzy danymi szerokimi a długimi
import pandas as pdimport matplotlib.pyplot as pltimport matplotlib as mpl# Wczytanie danychdane = pd.read_csv('dataset/sprzedaz.csv')# Dostosowanie kolorów dla lepszej czytelnościcolors = ['steelblue', 'crimson', 'forestgreen']markers = ['o', 's', '^']# Utworzenie wykresu dla każdego regionufor i, region inenumerate(dane['Region']): wartosci = dane.loc[dane['Region'] == region, ['Styczeń', 'Luty', 'Marzec', 'Kwiecień']].values.flatten() miesiace = ['Styczeń', 'Luty', 'Marzec', 'Kwiecień'] plt.plot(miesiace, wartosci, marker=markers[i], linestyle='-', linewidth=2.5, color=colors[i], label=region, markersize=8)# Dostosowanie wykresuplt.title('Sprzedaż w poszczególnych regionach w pierwszym kwartale', fontsize=16, pad=20)plt.xlabel('Miesiąc', fontsize=12)plt.ylabel('Wartość sprzedaży', fontsize=12)plt.grid(True, linestyle='--', alpha=0.7)# Poprawienie legendyplt.legend(title='Region', fontsize=10, title_fontsize=12)# Dostosowanie zakresu osi Y dla lepszej prezentacjiplt.ylim(min(dane[['Styczeń', 'Luty', 'Marzec', 'Kwiecień']].values.flatten()) -20,max(dane[['Styczeń', 'Luty', 'Marzec', 'Kwiecień']].values.flatten()) +30)# Poprawienie układuplt.tight_layout()# Wyświetlenie wykresuplt.show()
import seaborn as snsimport matplotlib.pyplot as pltimport pandas as pddf = pd.read_csv('dataset/sprzedaz.csv')df_long = df.melt( id_vars='Region', var_name='Miesiąc', value_name='Sprzedaż')print(df_long)sns.lineplot( data=df_long, x='Miesiąc', y='Sprzedaż', hue='Region')plt.show()
Region Miesiąc Sprzedaż
0 Północ Styczeń 200
1 Południe Styczeń 180
2 Zachód Styczeń 150
3 Północ Luty 220
4 Południe Luty 170
5 Zachód Luty 160
6 Północ Marzec 210
7 Południe Marzec 175
8 Zachód Marzec 155
9 Północ Kwiecień 230
10 Południe Kwiecień 190
11 Zachód Kwiecień 165